
GK110 Specifications
After diving into the technical documentation on NVIDIA’s new GK110 Kepler GPU, we give you all the details.
When the Fermi architecture was first discussed in September of 2009 at the NVIDIA GPU Technology Conference it marked an interesting turn for the company. Not only was NVIDIA releasing details about a GPU that wasn’t going to be available to consumers for another six months, but also that NVIDIA was building GPUs not strictly for gaming anymore – HPC and GPGPU were a defining target of all the company’s resources going forward.
Kepler on the other hand seemed to go back in the other direction with a consumer graphics release in March of this year without discussion of the Tesla / Quadro side of the picture. While the company liked to tout that Kepler was built for gamers I think you’ll find that with the information NVIDIA released today, Kepler was still very much designed to be an HPC powerhouse. More than likely NVIDIA’s release schedules were altered by the very successful launch of AMD’s Tahiti graphics cards under the HD 7900 brand. As a result, gamers got access to GK104 before NVIDIA’s flagship professional conference and the announcement of GK110 – a 7.1 billion transistor GPU aimed squarely at parallel computing workloads.
Kepler GK110
With the Fermi design NVIDIA took a gamble and changed directions with its GPU design betting that it could develop a microprocessor that was primarily intended for the professional markets while still appealing to the gaming markets that have sustained it for the majority of the company’s existence. While the GTX 480 flagship consumer card and the GTX 580 to some degree had overheating and efficiency drawbacks for gaming workloads compared to AMD GPUs, the GTX 680 based on Kepler GK104 has improved on them greatly. NVIDIA has still designed Kepler for high-performance computing though with a focus this time on power efficiency as well as performance though we haven’t seen the true king of this product line until today.

GK110 Die Shot
Built on the 28nm process technology from TSMC, GK110 is an absolutely MASSIVE chip built on 7.1 billion transistors and though NVIDIA hasn’t given us a die size, it is likely coming close the reticle limit of 550 square millimeters. NVIDIA is proud to call this chip the most ‘architecturally complex’ microprocessor ever built and while impressive, it means there is potential for some issues when it comes to producing a chip of this size. This GPU will be able to offer more than 1 TFlop of double precision computing power with greater than 80% efficiency and 3x the performance per watt of Fermi designs.

Continue reading our overview of the newly announced NVIDIA Kepler GK110 GPU!
There are several new features and technologies being introduced on the Kepler GK110 architecture including Dynamic Parallelism, Hyper-Q and NVIDIA GPUDirect that improve the capability of the GPU to function on its own with minimal CPU interruption required. Obviously the biggest change we are seeing with the chip is the pure performance it offers even compared to the GK104 we saw for the first time in March. GK110 uses the new SMX design with a 192 CUDA cores per unit though the number of and complexity of the SMX units has been increased.

GK110 GPU Block Diagram
The full GK110 chip is comprised of 15 SMX units for a total CUDA core count of 2,880 – compared to the 1,536 found in GK104 that is an 88% increase in functional units. NVIDIA’s documentation does indicate that ‘typical products’ will actually only use 13 of 14 of these SMX units so you should expect to see Tesla cards sporting either 2496 or 2688 CUDA cores.
There are some other changes you can see here from this block diagram representation including a move from a 256-bit memory bus on GK104 to a 384-bit memory bus using six 64-bit controllers in parallel. Memory speeds are not listed (neither are GPU clock speeds) since product announcements haven’t be made but I would hope to see these cards able to hit the same 6 Gbps that the GeForce cards are running at.
One of the key new features on GK104 was GPU Boost – the ability to increase the clock speed of the GPU when there was thermal and power headroom to do so. There is no indication of this feature in the GK110 whitepaper but I don’t see any reason why it would NOT be included as the technology is supposed to be application independent. We’ll be on the lookout for confirmation one way or the other here.
The L2 cache, which is used to share information between the SMX units, has been increased from 768K in Fermi to 1536K in Kepler.
For gear-heads that just want the information in a simple table form that compares the Fermi and Kepler GPU’s compute capabilities, this table was provided by NVIDIA.

The SMX units on GK110, while similar to those of GK104, add in processing units required for HPC and GPGPU workloads, most notably a set of two double precision units for every six single precision cores. That brings the core count to 192 single-precision units, 64 double-precision, 32 special function units and 32 load/store units.
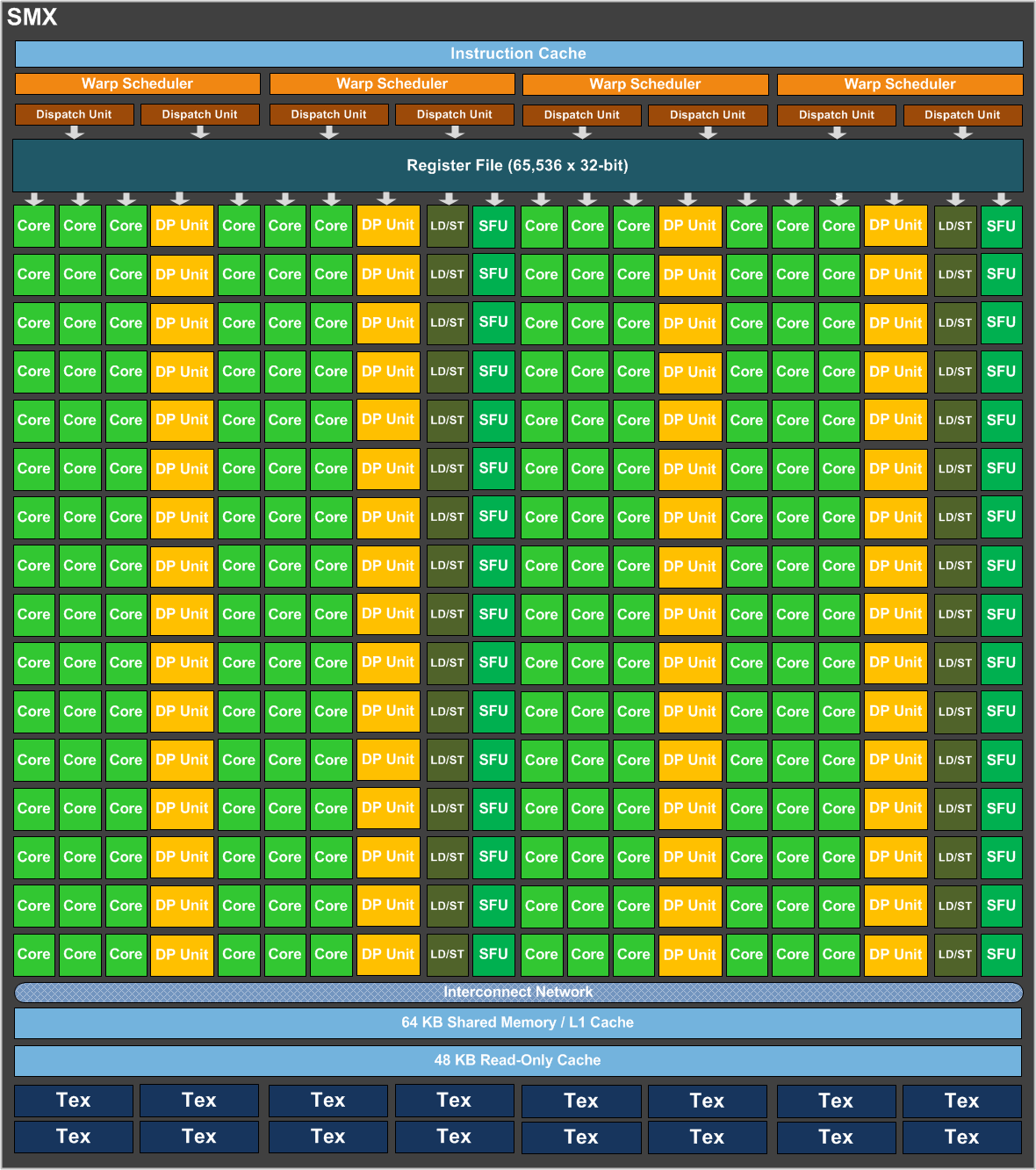
GK110 SMX Block Diagram
Each of the SMX units maintains the IEEE 754-2008 compliance that Fermi introduced though now with much faster overall compute.
Each SMX also includes four separate warp schedulers and eight instruction dispatchers that schedule collections of 32 threads called warps. With the dual instruction dispatchers per scheduler the Kepler architecture can now co-issue double precision commands in parallel with certain other non-register use functions like load/store and texture calls.
GK110 also sees an increase in the register file size compared to Fermi (64K vs. 32K) and Kepler allows for a 32K/32K split to the L1 cache and shared memory where Fermi only allowed 16K/48K divisions.


The die and transistor count
The die and transistor count is so crazy large that the usually cocky “Nvidia” admits that it isn’t that capable to produce the gk110 die with 100% functional cores.
The best you can expect is ~93% functional cores of the intended gpu die.
Not to say that ~ 6.6 billion die with some disabled modules instead f 7.1 billion transistors could be something to scuff about…
The price could be astronomical though, somewhere in the region of $ 3500.00 with mere 6 GB of GDDR memory.
Let it be known in the anals
Let it be known in the anals of history that on this day I called out the gk110 to be a 780 graphics card…of course their gonna make this into a graphics card, their a GRAPHICS CARD COMPANY…..yea it’ll be expensive but it’ll be uber, I PROMISE U
You mean “annals”, not butt
You mean “annals”, not butt holes.
Yes, but can it run Crysis?
Yes, but can it run Crysis?
Running Crysis at max
Running Crysis at max settings is the ultimate goal of the humankind. How do you expect it to be achieved with a miserable GK110? It will take thousands of generations of hardware. People will walk on terraformed Mars, but still unable to run Crysis. But someday… just someday… There is hope.
You made my day 🙂
You made my day 🙂
+1
+1
We’ll all be dead long before
We’ll all be dead long before you get what you want, so why even worry about it?
We’ll all be dead long before
We’ll all be dead long before you get what you want, so why even worry about it?
Tri sli. Nuff said.
Tri sli. Nuff said.